명사만 추출한 결과를 워드클라우드로 나타냈다.
word_dict = Counter(words_list)
tags = word_dict.most_common()
print(dict(tags))
wc = WordCloud(font_path='C:/Windows/Fonts/HMFMMUEX.TTC', background_color='white', width=800, height=600)
cloud = wc.generate_from_frequencies(dict(tags))
plt.figure(figsize=(10, 8))
plt.axis('off')
plt.imshow(cloud)
plt.show()
트리맵으로 나타내면 다음과 같은 모양이다.
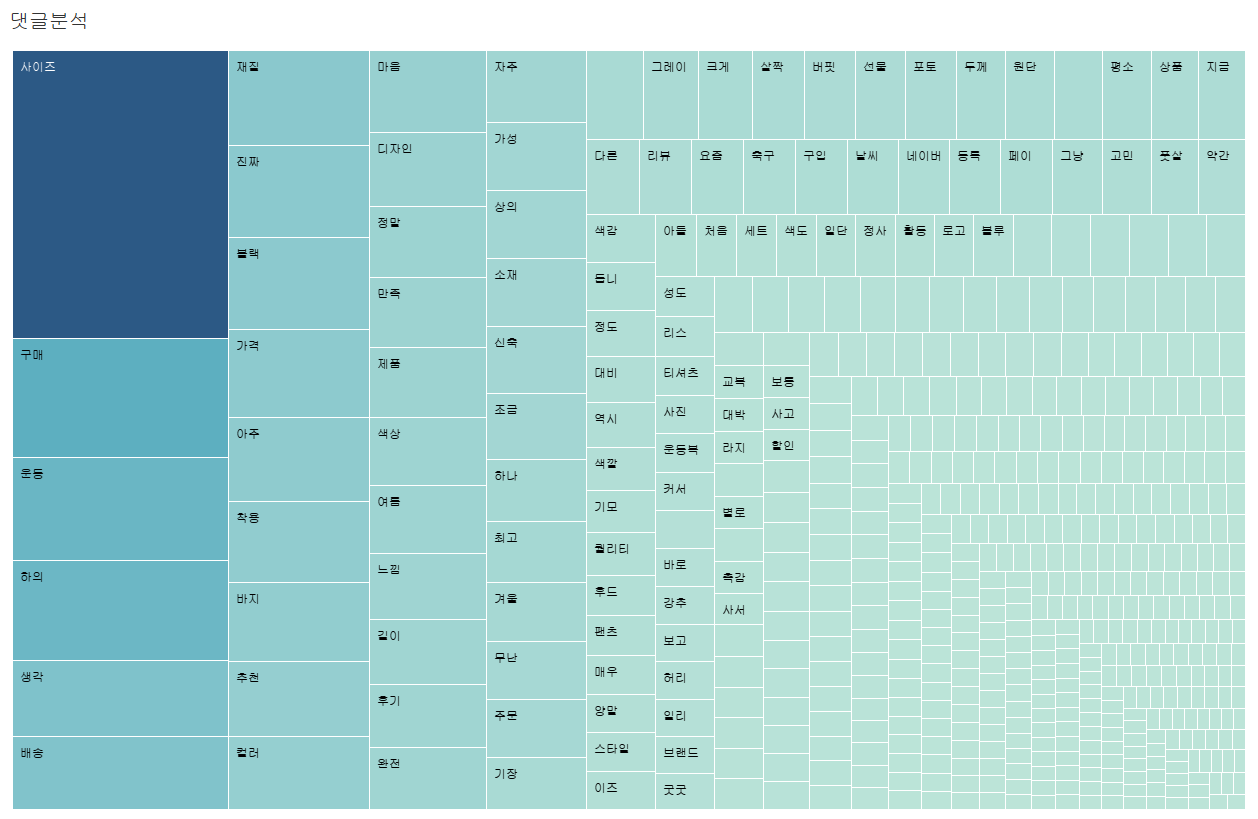
다른 정제 없이 추출한 명사를 기반으로 단어 빈도분석을 진행했다. 사이즈가 2500건 이상으로 가장 많이 나타났고, 구매, 운동, 하의, 생각, 배송, 재질 등의 순으로 나타났다. 명사만 추출한 것이기 때문에 이것만으로는 단어에 대한 구체적인 정보를 알 수는 없다. 그래도 몇가지 단어만 생각해보자.
1. 사이즈: 사이즈가 뭐 어떻다는거지에 대한 구체적인 정보를 알 수는 없지만 우리가 옷을 살때 생각해보면 사이즈라는 단어는 가장 먼저 생각하는 점이라서 옷에서 가장 많이 나오는 단어이지 않은가 싶다.
2. 운동: 라이프웨어 종류도 있지만 운동할때 입으려고 사나보구나 라는 점을 알 수 있다.
3. 하의: fcmm옷이 하의에 어떤 특징이 있나보다라고 생각된다. 구매건수, 평점 등 지금까지 본 것들을 생각해 봤을때 하의에 대한 정보가 계속 나타나고 있기 때문이다.
4. 배송: 배송이 빠르다는건지 느리다는건지는 알 수 없지만 배송에 대해서도 사람들이 이야기를 많이 하는것 같다.
5. 이외정보: 블랙 색상이 많이 나가고, 가성비가 좋은 옷이라는 정보를 알 수 있다.
이와 더불어 단어들의 단어들의 관계를 확인하기 위해 동시출현빈도 분석을 실시한다. 또한 이를 바탕으로 중심성 지수들을 구하여 시각화한다. 동시출현빈도분석의 개념은 특정 단어가 동시출현하는 비중이 높다면 그 단어는 중요하고 연관이 있는 단어라고 생각하는 것이다.
동시출현빈도를 구하기 위해 문서번호(로우) 단어(컬럼)로 이루어진 매트릭스를 만들어야 한다. 이를 DTM이라고 한다. DTM은 해당 문서에 특정 단어가 있으면 1, 없으면 0으로 표시하기 때문에 희소행렬이 된다. 아래 사진이 dtm을 db에 저장한 결과이다. 로우는 각 댓글, 컬럼에는 댓글에서 나온 모든 단어들이 있다. 현재 그림에서 3번 댓글에는 가격이라는 단어가 들어있다는 뜻이 된다.

DTM을 만들기 위해 이 과정을 진행했다.
1. 댓글에서 나온 단어 모두 텍스트 파일로 저장
2. sklearn의 CountVectorizer를 통해 DTM생성
3. 저장한 파일에서 의미있는 단어들을 다 지우고 의미가 없는 단어들만 남김(불용어 리스트)
4. 불용어 리스트를 불러와 DTM에서 사용할 컬럼만 남김
5. db저장
import pandas as pd
import numpy as np
from konlpy.tag import Okt
from collections import Counter
from sqlalchemy import create_engine
from tqdm import tqdm
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from analysis import get_dtm_array, get_words_freq
engine = create_engine("mysql+pymysql://root:123123@localhost/fcmm")
df = pd.read_excel("result/fcmm_review_cleaning.xlsx", index_col=0, sheet_name="cleaning2")
print(df.shape) #(11821, 8)
review_df = df[['id', 'product_code', 'writer', 'content']] #필요 컬럼만 추출
# print(review_df.isnull().sum()) # content에 499개 null값 존재
final_df = review_df.dropna() #null row 제거
print(final_df.shape) #(11338, 4)
okt = Okt()
words_list = []
cv = CountVectorizer() #객체선언
# 댓글 하나당 명사추출 후 문자열로 저장
sentence_num = final_df.shape[0]
# sentence_num = 1000
dtm_array, all_features = get_dtm_array(final_df, okt, cv, sentence_num, words_list)
#
# #분리된 모든 명사 txt파일로 저장
# # np.savetxt('result/all_words.txt', all_features, fmt='%s', delimiter=',', header='all_words', encoding='utf-8')
#dtm 저장
dtm_df = pd.DataFrame(dtm_array, columns=all_features) #데이터프레임 변환
print(f"original dtm_df shape: {dtm_df.shape}")
#-----불용어 가져오기
stopwords_file = open('result/stopwords.txt', 'r', encoding='utf-8')
stopwords_list = []
for line in stopwords_file.readlines()[1:]:
stopwords_list.append(line.strip())
stopwords_file.close()
stopwords_list = [word for i, word in enumerate(stopwords_list) if not stopwords_list[i]==""]
#-----불용어 컬럼에서 제거
dtm_df = dtm_df.drop(stopwords_list, axis='columns')
print(f"remove stopwords dtm_df shape: {dtm_df.shape}")
#-----실제 dtm_df
real_col = [col for col in list(dtm_df) if dtm_df[col].sum() > 1]
dtm_df = dtm_df[real_col]
print(f"real dtm_df shape: {dtm_df.shape}")
# db저장
dtm_df.to_sql(name="dtm", con=engine, index=False, if_exists="replace")
이후 생성한 DTM을 가지고 동시출현빈도분석을 실시하였다. 동시출현빈도를 구한모습은 아래와 같다. 나중엔 nltkv패키지의 ngram으로 해야지 그냥 할라니 복잡하다.

from sqlalchemy import create_engine
from tqdm import tqdm
from mysql import read_url
import pandas as pd
import numpy as np
engine = create_engine("mysql+pymysql://root:123123@localhost/fcmm")
data_sql = """
select * from dtm
"""
column_sql = """
SELECT COLUMN_NAME
FROM (
SELECT *
FROM INFORMATION_SCHEMA.COLUMNS
WHERE 1=1 AND TABLE_NAME='dtm'
) C;
"""
result = read_url(data_sql)
columns = read_url(column_sql)
columns = [col[0] for col in columns]
df = pd.DataFrame(result, columns=columns)
print(df.shape)
df_cols = list(df)
#-----단어 빈도수 저장할 dictionary
count_dict = {}
for doc_number in tqdm(range(df.shape[0])):
row = df.loc[doc_number] # 로우 가져오기
for i, word1 in enumerate(df_cols): #컬럼 순회
if row[word1]: #첫번째 단어 있으면
for j in range(i+1, len(df_cols)): #두번째 컬럼 부터 순회
if row[df_cols[j]]: #두번째 단어 있으면
# print(df_cols[i], df_cols[j]) #있는 애들끼리 출력
#dict에 저장
count_dict[df_cols[i], df_cols[j]] = count_dict.get((df_cols[i], df_cols[j]), 0) + max(row[word1], row[df_cols[j]])
#-----word1, word2, freq형태로 저장
count_list = []
for words in count_dict: #키만 출력
count_list.append([words[0], words[1], count_dict[words]])
#-----동시출현빈도 df저장
df = pd.DataFrame(count_list, columns=['word1','word2','freq'])
df = df.sort_values(by=['freq'], ascending=False)
df = df.reset_index(drop=True)
print(df.head())
df.to_sql("coherence", con=engine, index=False, if_exists="replace")
print("완료")
동시출현 빈도를 바탕으로 의미연결망 분석을 실시하였다. 의미연결망분석은 사회연결망분석기법을 텍스트의 단어에 적용한 것이다. 이는 분석대상들간의 관계를 연결망으로 표현하는 분석기법을 의미한다.어휘가 동시에 등장하면 서로 연결된 것으로 간주하여 이 연결 관계들을 분석하게 된다.
그럼 뭘 기준으로 연결할 것인지 정해야 한다.이때 사용되는 지표가 중심성이다. 중심성에는 연결중심성, 매개중심성, 근접
중심성, 위세중심성, 페이지랭크가 있다. 아래 링크에 자세한 설명이 나와있다.
[네트워크 분석] 네트워크 중심성(Centrality) 지수 - 연결(Degree), 매개(Betweeness), 위세(Eigenvector), 근
안녕하세요. 중심성(Centrality) 지수에 대해서 정리해보려고 합니다. 1. 중심성(Centrality) 지수 중심...
blog.naver.com

위에서 살펴본 중심성을 구하고 연결중심성과 페이지랭크를 통해 시각화 하였다. 원은 노드라고 부르고 선은 엣지라고 부른다. 노드 크기가 클수록 중요하게 등장하는 단어이다. 정제를 더 깔끔하게 하면 더 의미있는 것을 뽑아낼 수 있겠지만 현재로써 보면 그림상 봤을때 운동, 착용, 쇼핑몰, 블랙 등의 단어에서 원이 크게 나타나고 축구, 풋살등의 단어와 연관이 깊은것으로 나타난다.
import networkx as nx
import pandas as pd
import numpy as np
import networkx as nx
import operator
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
from mysql import read_url
DATA_SQL = """
SELECT * FROM COHERENCE;
"""
COLUMNS_SQL = """
SELECT COLUMN_NAME FROM (
SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE 1=1 AND TABLE_NAME="COHERENCE") C
;
"""
RESULT = read_url(DATA_SQL)
COLUMNS = read_url(COLUMNS_SQL)
COLUMNS = [col[0] for col in COLUMNS]
dataset = pd.DataFrame(RESULT, columns=COLUMNS)
print(dataset.head(10))
#----- 중심성 구하기
"""
중심성은 Graph에 edge를 추가하여 구한다.
연결, 매개, 근접, 위세, 페이지랭크 다섯가지가 있다.
"""
G_centrality = nx.Graph()
for i in range(len(dataset[dataset['freq']>=10])):
G_centrality.add_edge(dataset['word1'][i], dataset['word2'][i], weight=dataset['freq'][i])
dgr = nx.degree_centrality(G_centrality)#연결중심성
btw = nx.betweenness_centrality(G_centrality)#매개
cls = nx.closeness_centrality(G_centrality)#근접
egv = nx.eigenvector_centrality(G_centrality)#위세
pgr = nx.pagerank(G_centrality) #페이지랭크
print("연결중심성", dgr)
print("매개중심성", btw)
print("근접중심성", cls)
print("위세중심성", egv)
print("페이지랭크", pgr)
sorted_dgr = sorted(dgr.items(), key=lambda item: item[1], reverse=True)
sorted_btw = sorted(btw.items(), key=lambda item: item[1], reverse=True)
sorted_cls = sorted(cls.items(), key=lambda item: item[1], reverse=True)
sorted_egv = sorted(egv.items(), key=lambda item: item[1], reverse=True)
sorted_pgr = sorted(pgr.items(), key=lambda item: item[1], reverse=True)
print("정렬 연결중심성", sorted_dgr)
print("정렬 매개중심성", sorted_btw)
print("정렬 근접중심성", sorted_cls)
print("정렬 위세중심성", sorted_egv)
print("정렬 페이지랭크", sorted_pgr)
#----- 중심성 수치를 가지고 그래프 그리기
G = nx.Graph() #그릴 그래프
for i in range(len(sorted_dgr)):
#노드추가: 노드크기는 연결중심성 크기로
G.add_node(sorted_pgr[i][0], size=sorted_dgr[i][1])
for ind in range((len(np.where(dataset['freq'] >=10)[0]))):
#엣지추가: 노드와 노드에 맞게 weight는 freq로
G.add_weighted_edges_from([(dataset['word1'][ind], dataset['word2'][ind], int(dataset['freq'][ind]))])
font_fname = 'C:/Windows/Fonts/HMFMMUEX.TTC'
fontprop = fm.FontProperties(fname=font_fname, size=18).get_name()
# 노드 크기 조정
sizes = [G.nodes[node]['size'] *500 for node in G]
nx.draw(G, node_size=sizes, with_labels=True, font_family=fontprop)
plt.show()'Data Analysis > FCMM' 카테고리의 다른 글
| fcmm 댓글 분석 (0) | 2023.07.20 |
|---|---|
| fcmm 데이터시각화2 (0) | 2023.07.20 |
| fcmm 데이터 분석(중분류 NULL은 왜?) (0) | 2023.07.19 |
| FCMM데이터 시각화 (0) | 2023.07.18 |
| fcmm테이블 모델링 (0) | 2023.07.18 |


