#-------------- apriori 사용
#파라미터 설정
params <- list(
supp=0.01, conf=0.3
);
#규칙생성
rules <- apriori(Groceries, parameter = params);
#연관규칙 결과 확인
inspect(rules);
inspect(sort(rules, by="lift", decreasing=T)[1:5]) #향상도기준 내림차순 5개
코드에서와 같이 최소지지도를 0.01로, 신뢰도를 0.3으로 지정하여 apriori에 적용
125개의 규칙이 생성됨
향상도를 기준으로 내림차순 정렬한 연관규칙 5개만 확인
파라미터 적용 규칙생성
support는 좌항과 우항이 함께 구매될 확률
confidence는 좌항과 우항의 연관 관계의 정도
lift는 좌항의 제품 구매시 우항의 제품 구매할 확률이 n배 라는 의미
향상도기준 내림차순으로 정렬한 연관규칙 5개 출력
출력된 규칙에서 [1]과 [4]는 lhs(좌항)과 rhs(우항)이 겹치는 것을 확인할 수 있다.
중복되는 규칙은 없애기 위해 함수를 구현(arules패키지는 중복 가지치기 함수를 제공하지 않음)
drop_dup_rules <- function(rules) {
test_rules_matrix <- is.subset(rules, rules, sparse=F) #lhs와 rhs결합 x, y축 동일한 행렬 만들기
like_matrix <- lower.tri(test_rules_matrix, diag=T); #삼각함수를 이용해 test_rules_matrix과 모양 같은 bool행렬 만들기
test_rules_matrix[like_matrix] <- NA; #bool행렬에서 True부분을 NA로 변경
dup_rules <- colSums(test_rules_matrix, na.rm=T) >= 1; #컬럼별 합계 구하여 중복 체크
pruned_rules <- rules[!dup_rules]#false인 컬럼만 살리기(중복없다는 뜻)
return (pruned_rules);
}
특정 rhs를 구매하게 만드는 lhs를 찾기 위한 연관규칙 생성
support(최소지지도): 0.001, confidence(신뢰도): 0.5, minlen(좌항과 우항을 합친 최소 물품 수: 2)
soda를 구매하게 만드는 lhs를 찾기
실행결과를 나타내기
#----------------------우변의 구매를 이끌 아이템 세트 찾기
#파라미터 적용
params <- list(
supp=.001,
conf=.5,
minlen=2
);
#soda를 구매하게 만드는 lhs찾기
appearance <- list(
default="lhs", rhs="soda"
);
#실행결과 나타내기
control <- list(verbose=T);
#규칙생성
rules = apriori(
data=Groceries,
parameter=params,
appearance=appearance,
control=control
);
#중복제거 함수 적용
rules <- drop_dup_rules(rules);
#신뢰도 기준으로 내림차순 정렬
rules <- sort(rules, by="confidence", decreasing=F);
#연관 규칙 확인
inspect(rules);
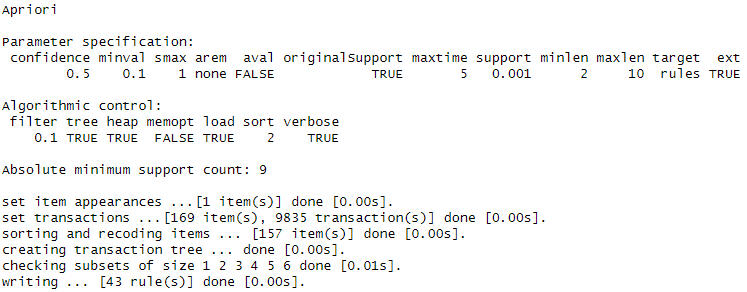
파리미터에 명시된대로 규칙 생성됨(control에서 verbose=T로 설정했기 때문에 해당 결과 나타남)
중복 제거 전 43개 규칙이 생성됨
규칙생성 결과
중복제거 후 41개의 규칙만 남음
신뢰도 기준으로 오름차순 정렬 실시
coffee, misc.beverage를 함께 구매할 경우 soda를 구매하는 확률이 77%로 가장 높게 나타났다.
중복제거 후 신뢰도 기준 내림차순한 결과
특정 lhs를 구매하게 만드는 rhs를 찾기 위해 연관규칙 생성
#최소지지도, 신뢰도, 최소집합 수 설정
params2 <- list(
supp=0.001,
conf=0.3,
minlen=2
);
#특정 lhs를 찾기 위한 rhs
appearance2 <- list(
default="rhs",
lhs=c("yogurt", "sugar")
);
#실행결과 숨기기
control <- list(verbose=F);
#규칙생성
rules2 <- apriori(Groceries, parameter=params2, appearance=appearance2, control=control);
#중복제거
rules2 <- drop_dup_rules(rules2);
#신뢰도를 기준으로 오름차순 정렬한 규칙 확인
inspect(sort(rules2, by="confidence", decreasing = F));
control의 verbose를 FALSE로 설정했기 때문에 실행한 요약결과는 나타나지 않는다.
규칙을 확인한 결과 총 6개의 규칙이 나타났다.
yogurt or sugar와 연관이 가장 높은 제품은 whole milk임을 알 수 있다.
예시 3) lotto데이터 활용
859회 로또 당첨번호 가지고 있는 데이터
변수설명
time_id: 회차
num1 ~ num6: 1번부터 6번까지의 번호
#데이터 로드
lotto <- read.csv("lotto.csv");
head(lotto);
로드된 데이터
num1 ~ num6는 회차당 6개의 숫자이므로 long form으로 데이터 변환
melt함수 사용
#데이터 형태 변환 패키지 로드
install.packages("reshape2");
library(reshape2);
#데이터 형태 변환: melt
lotto_melt <- melt(lotto, id.vars=1); #첫번째 열을 기준으로 melt
lotto_melt <- lotto_melt[,-2]; #두번째 열 삭제
str(lotto_melt); #변환된 데이터 확인
melt하여 정제한 데이터
apriori 함수를 적용하기 전 transaction데이터로 변환해야 함
transaction데이터로 변환하기 전 회차별 번호로 분리
#----------트랜잭션 데이터로 변환
#회차별 번호로 분리
lotto_sp <- split(lotto_melt$value, lotto_melt$time_id);
#회차별 트랜잭션 데이터로 변환
lotto_ts <- as(lotto_sp, "transactions");
#결과확인
inspect(lotto_ts[1:5]);
트랜잭션 데이터로 변환
가장 많이 나타난 숫자 시각화: itemFrequencyPlot(x, topN, type)